
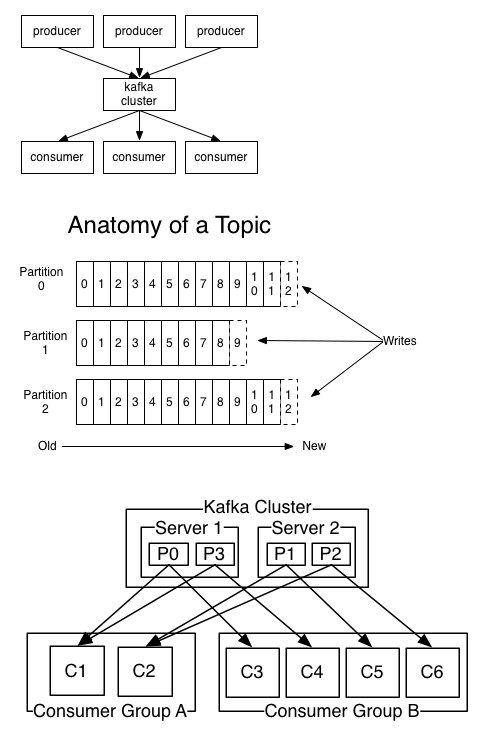
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
Kafka 详细介绍
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
支持通过kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。
卡夫卡的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
值得关注的新特性
KIP-290 adds support for prefixed ACLs, simplifying access control management in large secure deployments. Bulk access to topics, consumer groups or transactional ids with a prefix can now be granted using a single rule. Access control for topic creation has also been improved to enable access to be granted to create specific topics or topics with a prefix.
KIP-255 adds a framework for authenticating to Kafka brokers using OAuth2 bearer tokens. The SASL/OAUTHBEARER implementation is customizable using callbacks for token retrieval and validation.
Host name verification is now enabled by default for SSL connections to ensure that the default SSL configuration is not susceptible to man-in-the-middle attacks. You can disable this verification if required.
You can now dynamically update SSL truststores without broker restart. You can also configure security for broker listeners in ZooKeeper before starting brokers, including SSL keystore and truststore passwords and JAAS configuration for SASL. With this new feature, you can store sensitive password configs in encrypted form in ZooKeeper rather than in cleartext in the broker properties file.
The replication protocol has been improved to avoid log divergence between leader and follower during fast leader failover. We have also improved resilience of brokers by reducing the memory footprint of message down-conversions. By using message chunking, both memory usage and memory reference time have been reduced to avoid OutOfMemory errors in brokers.
Kafka clients are now notified of throttling before any throttling is applied when quotas are enabled. This enables clients to distinguish between network errors and large throttle times when quotas are exceeded.
We have added a configuration option for Kafka consumer to avoid indefinite blocking in the consumer.
We have dropped support for Java 7 and removed the previously deprecated Scala producer and consumer.
Kafka Connect includes a number of improvements and features. KIP-298 enables you to control how errors in connectors, transformations and converters are handled by enabling automatic retries and controlling the number of errors that are tolerated before the connector is stopped. More contextual information can be included in the logs to help diagnose problems and problematic messages consumed by sink connectors can be sent to a dead letter queue rather than forcing the connector to stop.
KIP-297 adds a new extension point to move secrets out of connector configurations and integrate with any external key management system. The placeholders in connector configurations are only resolved before sending the configuration to the connector, ensuring that secrets are stored and managed securely in your preferred key management system and not exposed over the REST APIs or in log files.
We have added a thin Scala wrapper API for our Kafka Streams DSL, which provides better type inference and better type safety during compile time. Scala users can have less boilerplate in their code, notably regarding Serdes with new implicit Serdes.
Message headers are now supported in the Kafka Streams Processor API, allowing users to add and manipulate headers read from the source topics and propagate them to the sink topics.
Windowed aggregations performance in Kafka Streams has been largely improved (sometimes by an order of magnitude) thanks to the new single-key-fetch API.
We have further improved unit testibility of Kafka Streams with the kafka-streams-testutil artifact.
可以看到,从该版本起,已经放弃对 Java 7 的支持,并移除了之前弃用的 Scala 生产者和消费者。
∨ 展开

 Eclipse4.9 64位破解 4.9 x64版
Eclipse4.9 64位破解 4.9 x64版 Eclipse4.7 32位 4.7RC1 中文版
Eclipse4.7 32位 4.7RC1 中文版 Eclipse4.8汉化包 16.0 Photon版
Eclipse4.8汉化包 16.0 Photon版  MyEclipse CI 最新版 2023.0.1 中文版
MyEclipse CI 最新版 2023.0.1 中文版 TortoiseSVN简体中文语言包 1.13.1.286
TortoiseSVN简体中文语言包 1.13.1.286 .NET Core SDK 3.1.424 正式版
.NET Core SDK 3.1.424 正式版 PHP 7.0 64位 7.0.33
PHP 7.0 64位 7.0.33 XAMPP for Windows 5.6.39 中文版
XAMPP for Windows 5.6.39 中文版 Intel Parallel Studio XE 2018破解版
Intel Parallel Studio XE 2018破解版 GNOME桌面环境 3.30
GNOME桌面环境 3.30 Zend Studio 12中文汉化版 12.5.1 免费版
Zend Studio 12中文汉化版 12.5.1 免费版








 Java SE Development Kit 10稳定版
Java SE Development Kit 10稳定版 Java的工具包Jtop.jar免费版
Java的工具包Jtop.jar免费版 NetBeans IDE For HTML5中文版
NetBeans IDE For HTML5中文版 Java卸载工具正式版
Java卸载工具正式版 Java 常用工具包 Jodd
Java 常用工具包 Jodd Eclipse IDE for Java Developers 32位中文版
Eclipse IDE for Java Developers 32位中文版 Java 工具集Hutool
Java 工具集Hutool Javascript 测试框架 Mocha
Javascript 测试框架 Mocha ECshop 3.6破解 3.6 特别版
ECshop 3.6破解 3.6 特别版 FastReport.NET 2018 破解 2018 免费版
FastReport.NET 2018 破解 2018 免费版 Kotlin实战PDF 11.0 汉化版
Kotlin实战PDF 11.0 汉化版 MyEclipse 2017 CI7 破解工具 17.0 免费版
MyEclipse 2017 CI7 破解工具 17.0 免费版 Gradle5.2All 5.2.1 完整版
Gradle5.2All 5.2.1 完整版 EA Architect 13破解 13.0 免费版
EA Architect 13破解 13.0 免费版 Java JDK9 Windows 9.0.4 兼容版
Java JDK9 Windows 9.0.4 兼容版 MyEclipse CI 2023Windows
MyEclipse CI 2023Windows Python for Windows32位 3.10.8
Python for Windows32位 3.10.8 DevOps自动化组件RunDeck 2.10.5 官方版
DevOps自动化组件RunDeck 2.10.5 官方版