
Nutch是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本之后,Nutch已经从搜索引擎演化为网络爬虫,接着Nutch进一步演化为两大分支版本:1.X和2.X,这两大分支最大的区别在于2.X对底层的数据存储进行了抽象以支持各种底层存储技术。Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎.
Apache Nutch v2.3已经发布了,建议所有使用2.X系列的用户和开发人员升级到这个版本。
这个版本提供了一个基于Apache Wicket的Web管理界面,解决了143个问题,提供了Maven依赖,升级到Gora v0.5,支持的底层存储为:
Apache Hadoop 1.0.1 & 2.4.0
Apache Cassandra 2.0.2
Apache HBase 0.94.14
Apache Accumulo 1.5.1
MongoDB 2.12.2
Apache Solr 4.8.1
Apache Avro 1.7.6
同时请注意,Gora对SQL的支持已经过时了。
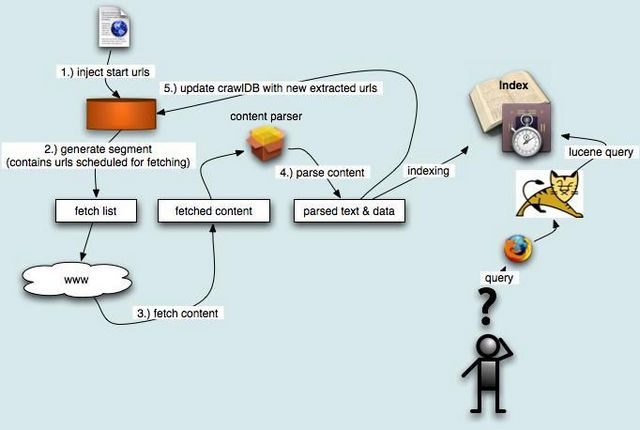
工作流程编辑
在创建一个WebDB之后(步骤1), “产生/抓取/更新”循环(步骤3-6)根据一些种子URLs开始启动。当这个循环彻底结束,Crawler根据抓取中生成的segments创建索引(步骤7-10)。在进行重复URLs清除(步骤9)之前,每个segment的索引都是独立的(步骤8)。最终,各个独立的segment索引被合并为一个最终的索引index(步骤10)。
其中有一个细节问题,Dedup操作主要用于清除segment索引中的重复URLs,但是我们知道,在WebDB中是不允许重复的URL存在的,那么为什么这里还要进行清除呢?原因在于抓取的更新。比方说一个月之前你抓取过这些网页,一个月后为了更新进行了重新抓取,那么旧的segment在没有删除之前仍然起作用,这个时候就需要在新旧segment之间进行除重。
∨ 展开
 自在搜桌面搜索软件 1.0.0.4 绿色版
自在搜桌面搜索软件 1.0.0.4 绿色版 鹰眼快搜硬盘搜索工具 2.1 2018
鹰眼快搜硬盘搜索工具 2.1 2018 淘宝店铺seo搜索分析软件 1.0 免费版
淘宝店铺seo搜索分析软件 1.0 免费版 狂人采集器 1.0 免费版
狂人采集器 1.0 免费版 SEO引擎优化指南 2.0
SEO引擎优化指南 2.0 远方极速搜索 2.0
远方极速搜索 2.0 BreakPrisonSearch越狱搜索 2.5
BreakPrisonSearch越狱搜索 2.5 百度+客户端 1.1.0.817
百度+客户端 1.1.0.817 Easyn搜索配置工具中文绿色版
Easyn搜索配置工具中文绿色版 搜索助手
搜索助手 百度资源搜索神器
百度资源搜索神器 蓝光魔框搜索正式版
蓝光魔框搜索正式版 超级搜索王
超级搜索王 博购搜索百度版
博购搜索百度版 快搜神器最新免费版
快搜神器最新免费版 everything 搜索软件中文版 1.4.1.1022 中文版
everything 搜索软件中文版 1.4.1.1022 中文版 网站搜索吾爱破解 5.10 绿色版
网站搜索吾爱破解 5.10 绿色版 智能SEO关键词优化工具 12.5
智能SEO关键词优化工具 12.5 网页内容更新提醒软件 1.0
网页内容更新提醒软件 1.0 快搜盒子客户端 1.0
快搜盒子客户端 1.0 BoodiGo搜索引擎 1.0
BoodiGo搜索引擎 1.0 设鬼搜索 1.3.2.0
设鬼搜索 1.3.2.0 比目鱼bt搜索 5.5.15156.2340 中文绿色版
比目鱼bt搜索 5.5.15156.2340 中文绿色版 搜图神器LibreStock 1.0.0
搜图神器LibreStock 1.0.0